Ivy Tests#
On top of the Array API test suite, which is included as a submodule mapped to the folder test_array_api, there is also a collection of Ivy tests, located in subfolder test_ivy.
These tests serve two purposes:
test functions and classes which are not part of the standard
test additional required behaviour for functions which are part of the standard. The standard only mandates a subset of required behaviour, which the Ivy functions generally extend upon.
As done in the test suite, we also make use of hypothesis for performing property based testing.
Testing Pipeline#

An abstract look at Ivy testing cycle.
Test Data Generation: At this stage, we generate our test data for the testing function, using Hypothesis and test helpers strategies. This is the most important step, we should ensure that our data generation is complete and covers all of the possible inputs. We generate the input data inside the
@givendecorator that wraps every test.Pre-execution Test Processing: After the data is generated, more input processing is needed before testing the function. This is more specific to which functions are we testing, core functions require a different input processing from frontend functions. One of the required pre-processing steps for any test function is converting the array input to a valid framework specific array, later in the testing process we call the backend framework function, for example TensorFlow’s
absfunction requires the input to be atf.Tensor, not an ivy.Array.Test Execution: After the input data is generated and processed, we assert that the result of the functions is correct, this includes, asserting the result has the correct values, shape, and data type. And that this is consistent across all of our backends.
Note
Some functions are not tested for values when this is not possible, for example, we can not assert that random functions produce the same values, in this case, we should assert that the data has some properties, asserting that the values have specified bounds is a good start.
Test Results: If a test fails, Hypothesis and test helpers will print an exhaustive log. Including the generated test case, the results of the function, etc.
Hypothesis#
Using pytest fixtures (such as the ones removed in this commit) causes a grid search to be performed for all combinations of parameters.
This is great when we want the test to be very thorough, but can make the entire test suite very time consuming.
Before the changes in this commit, there were 300+ separate tests being run in total, just for this ivy.abs() function.
If we take this approach for every function, we might hit the runtime limit permitted by GitHub actions.
A more elegant and efficient solution is to use the Hypothesis module, which intelligently samples from all of the possible combinations within user-specified ranges, rather than grid searching all of them every single time.
The intelligent sampling is possible because Hypothesis enables the results of previous test runs to be cached, and then the new samples on subsequent runs are selected intelligently, avoiding samples which previously passed the tests, and sampling for unexplored combinations.
Combinations which are known to have failed on previous runs are also repeatedly tested for.
With the uploading and downloading of the .hypothesis cache as an artifact, these useful properties are also true in Ivy’s GitHub Action continuous integration (CI) tests.
Rather than making use of pytest.mark.parametrize, the Ivy tests make use of Hypothesis search strategies.
This reference commit outlines the difference between using pytest parametrizations and Hypothesis, for ivy.abs().
Among other changes, all pytest.skip() calls were replaced with return statements, as pytest skipping does not play nicely with Hypothesis testing.
Data Generation#
We aim to make the data generation for three out of the four kinds of ivy functions exhaustive; primary, compositional, and mixed.
Exhaustive data generation implies that all possible inputs and combinations of inputs are covered.
Take finfo , for example.
It can take either arrays or dtypes as input, hence the data generation reflects this using the bespoke search strategy _array_or_type.
However, such rigorous testing is not necessary for standalone functions (those that are entirely self-contained in the Ivy codebase without external references).
These kinds of functions may only require standard Pytest testing using parametrize, e.g. test_default_int_dtype.
For further clarity on the various Function Types in ivy.
The way data is generated is described by the hypothesis.strategies module which contains a variety of methods that have been used widely in each of Ivy’s functional and stateful submodule tests.
An initialized strategy is an object that is used by Hypothesis to generate data for the test.
For example, let’s write a strategy that generates a random data type -:
Let’s define a template function for printing examples generated by the Hypothesis integrated test functions.
>>> def print_hypothesis_examples(st: st.SearchStrategy, n = 3):
>>> for i in range(n):
>>> print(st.example())
>>> dtypes = ("int32", "uint32", "float32", "bool")
>>> custom_strategy = st.sampled_from(dtypes)
>>> print_hypothesis_examples(custom_strategy)
float32
bool
uint32
Note - : The output will be randomised in each run. This is quite a simplistic example and does not cover the intricacies behind the helper functions in the test_ivy directory.
We are simply sampling a random data type from the set dtypes, for example this can be used to generate data for the parameter dtype for ivy.ones.
To call an example from the strategy, we use the method example() to generate a random example from the strategy, this is only for experimenting purposes, we should not use it during the actual test.
In the example above, st.sampled_from is what we call a strategy.
To briefly describe -:
sampled_from accepts a collection of objects. This strategy will return a value that is sampled from this collection.
lists accepts another strategy which describes the elements of the list being generated. This is best used when a sequence of varying lengths is required to be generated, with elements that are described by other strategies.
Writing your own strategy#
We will not be covering all of the strategies that Hypothesis provide, but to give you a glance of what they’re capable of, we will briefly explain some of the strategies and write a new strategy to be used later for testing. Read more about strategies on Hypothesis docs.
integers - generates integers values within a given range.
none - returns a strategy which only generates None.
one_of - This allows us to specify a collection of strategies and any given datum will be drawn from “one of” them. Hypothesis has the pipe operator overloaded as a shorthand for
one_of.composite - This provides a decorator, which permits us to form our own strategies for describing data by composing Hypothesis built-in strategies
Suppose you need to generate a 1-D array or a scaler value, which also generates an index of an element if an array is generated, otherwise None.
@st.composite
def array_or_scaler(draw):
values = draw(st.integers() | st.lists(st.integers()))
if isinstance(values, list) and values:
len_of_array = len(values)
index = draw(st.integers(min_value=0, max_value=len_of_array-1))
else:
index = st.none()
return values, index
we can then later use this strategy in any of our tests.
Writing Hypothesis Tests#
Writing Hypothesis tests are intuitive and simple, as an example, we’ve implemented our own add function, which takes in 2 parameters x and y.
We would like to run a test and compare it to Python + operator, and assert it returns the same values.
def add(x, y):
return y + x
@given(
x=st.integers()
y=st.integers()
)
def test_add(x, y):
assert x + y == add(x, y)
At first, we define our function
add, which simply returnsy + x.Defining a test function, which basically assert that the result of
x + yis exactly equal toadd(x, y).
3. Add Hypothesis @given decorator, passing two keyword arguments, x and y each corresponds to the variables we are going to run the test
on, @given is our entry point to Hypothesis, it expects a strategy to be passed in, describing what kind of data to generate, for our example, we choose to only test for integers using st.integers() strategy.
Ivy Test Decorators#
Why do we need to handle test decorators?
In order to run a test, a lot of pre-processing must be done, e.g. import the function, does it support complex data type? does it run on CPU? how many parameters does it take? are they positional or keyword only, or both? and a lot of information about the function that is being tested, this allows us later to run the test efficiently and in a complete way. All of this happens at collecting time.
What do the handle test decorators do?
Generate the test flags: 1.
native_arrayflags 2.as_variableflags 3.with_outflagGenerate
num_positional_args
The flags that the decorators would generate, may be more or less depending on the function, Ivy Functional API requires gradient_test flag, some test functions like test_gpu_is_available does not require any of these flags, and therefore the decorator will not generate any of these.
Generate test specific parameters,
fn_name,fn_tree,method_tree.Check for the function’s supported data types and devices.
Implicitly wraps the test function using Hypothesis
@givendecorator, this allows us to write less code, more readable, and easy to update and maintain.
This is not an exhaustive list of what the handle_test decorators actually do, they may do more or less in the future, to summarize, the test decorators do some of the Pretest-processing part in the testing pipeline.
Why do we have multiple handle test decorators?
Having multiple test decorators is mainly for efficiency, handle_test could do what handle_frontend_test does, it just handles the parameters slightly different, and this can be inferred at run time, but we choose to separate the decorator for general different usages, currently we have 5 separate decorators
handle_testhandle_methodhandle_frontend_testhandle_frontend_methodhandle_example
One of the few differences between the 5 decorators is that they generate different kinds of flags, some generate more or less, but they all share the same general structure.
Integration
Our test decorators actually transforms to @given decorators at PyTest collecting time, therefore this allows us to use other Hypothesis decorators like, @reproduce_failure, @settings, @seed.
Writing Ivy Tests#
As mentioned previously, testing Ivy functions needs a lot of pre-processing and past-processing, using only given decorator would not be sufficient
to write an effective test, the following example describes how to implement a test for the function ivy.abs, using our test decorators and test helpers.
Integration of Strategies into Ivy Tests#
Once a strategy is initialised the @given decorator is added to the test function for drawing values from the strategy and passing them as inputs to the test.
For example, in this code snippet here -:
@handle_test(
dtype_and_x=helpers.dtype_and_values(available_dtypes=helpers.get_dtypes("numeric")),
)
Let’s take a deeper look at ivy.abs, according to the function signature, it accepts two arguments, x which can be a Python numeric or an ivy.Array of numeric data type, and an out optional output array.
Using a lot of help from test helpers, we can simply generate a random input that covers all the possible combinations using dtype_and_values composite strategy, specifying the list of data types to sample from by also using another composite strategy get_dtypes which samples a valid data types according to the backend that is tested.
For out keyword argument, the @handle_test decorator generates a boolean for whether we should provide an out argument or not, thankfully, the test_function helper function does a lot under the hood to properly create an array for the out argument.
If the function does not support the out, we should explicitly specify that we should not generate boolean flags for out by setting with_out=False, the @handle_test in this case will not generate a value for with_out.
As discussed above, the helper functions use the composite decorator, which helps in defining a series of custom strategies.
It can be seen that dtype_and_x uses the code:dtype_and_values strategy to generate numeric data types(for more details, see the section below) and corresponding array elements, whose shapes can be specified manually or are randomized by default.
The generated data is returned as a tuple.
One thing to note here is the test_flags variable in the test function. This is basically an object which is initialized internally, which captures all the flags mentioned above for the test during collection time. These flags are then available for the helper function at test time.
The test flags can also be generated explicitly like this -:
@handle_test(
as_variable_flags = st.lists(st.booleans(), min_size = <any>, max_size = <any>),
native_array_flags = st.lists(st.booleans(), min_size = <any>, max_size = <any> ),
container_flags = st.lists(st.booleans(), min_size= <any>, max_size= <any>), # <any> integer value can be passed
test_instance_method = st.just(<bool>), # <bool> can either be True or False
test_with_out = st.just(<bool>),
test_gradients = st.just(<bool>),
test_inplace = st.just(<bool>),
)
In the test above test_abs, one can assume that these flags are automatically loaded inside the test_flags object with default values.
Test flags are mostly similar across decorators with slight differences in the variable names. This is how we generate them for method testing.
The only difference here is that the test_flags object here is divided in two, the init_flags and the method_flags. The above standards are extended
to the handle_frontend_test and handle_frontend_method respectively.
Let’s look at the data produced by this strategy -:
>>> print_hypothesis_examples(dtype_and_values(), 2)
(['int8'], [array(69, dtype=int8)])
(['int8'], [array([-23, -81], dtype=int8)])
These values are then unpacked, converted to ivy.Array class, with corresponding dtypes.
The test then runs on the newly created arrays with specified data types.
Adding Explicit Examples to tests#
In certain cases where we’d like to test certain examples explicitly which are outliers and it isn’t feasible to define them as a strategy,
we can use the @handle_example decorator. One such example is `this`_ where we need to test ivy.set_item with slice objects.
Hypothesis allows us to test with an explicit example deterministically using the `@example`_ decorator. Our @handle_example decorator is a wrapper around this.
Which helps us to use the default values of the test_flags, method_flags allowing us to easily test explicit examples for the ivy functional tests, frontend_tests, methods, and frontend_methods.
We have to pass one of the following 4 arguments as True to the @handle_example decorator depending on what test we are dealing with.
1. test_example
2. test_frontend_example
3. test_method_example
4. test_frontend_method_example
The following example shows, how we can use the @handle_example decorator to test the one of the frontend functions by adding an explicit example.
Why do we need helper functions?#
It is usually the case that any ivy function should run seamlessly on ‘all the possible varieties, as well as the edge cases’ encountered by the following parameters -:
All possible data types - composite
Boolean array types if the function expects one - composite
Possible range of values within each data type - composite
When input is a container - boolean
When the function can also be called as an instance method - boolean
When the input is a native array - boolean
Out argument support, if the function has one - boolean
Note -: Each test function has its own requirements and the parameter criterion listed above does not cover everything.
Sometimes the function requirements are straight-forward, for instance, generating integers, boolean values, and float values. Whereas, in the case of specific parameters like -:
array_values
data_types
valid_axes
lists or tuples or sequence of varied input types
generating subsets
generating arbitrary shapes of arrays
getting axes at
We need a hand-crafted data generation policy (composite). For this purpose ad-hoc functions have been defined in the test helpers. It might be appropriate now, to bring them up and discuss their use. A detailed overview of their working is as follows-:
- get_dtypes - draws a list of valid data types for the test at run time, valid data types are not only data types that are supported by the backend framework.
For frontend functions, these are the intersection of the frontend framework and the backend framework supported data types. We should be always using this helper function whenever we need to sample a data type.
>>> print_hypothesis_examples(helpers.get_dtypes(kind="integer"), 1)
['int8', 'int16', 'int32', 'int64', 'uint8', 'uint16', 'uint32', 'uint64']
>>> print_hypothesis_examples(helpers.get_dtypes(kind="numeric", full=False), 3)
['uint64']
['float16']
['int8']
- dtype_and_values - This function generates a tuple of NumPy arrays and their data types.
Number of arrays to generate is specified using
num_arraysparameter, generates 1 array by default.
>>> print_hypothesis_examples(helpers.dtype_and_values(), 3)
(['bool'], [array([ True, True, True, False])])
(['float64'], [array(-2.44758124e-308)])
(['int16'], [array([[-11228, 456], [-11228, -268]], dtype=int16)])
This function contains a list of keyword arguments.
To name a few, available_dtypes, max_value, allow_inf, min_num_dims etc.
It can be used wherever an array of values is expected.
That would again be a list of functions which expects at least one ivy.Array.
dtype_values_axis - Similar to dtype_and_values, generates an associated valid axis for the array.
>>> print_hypothesis_examples(helpers.dtype_values_axis(), 3)
(['int16'], [array([ -9622, 28136, 6375, -12720, 21354 -4], dtype=int16)], 0)
(['float16'], [array([-1.900e+00, 5.955e+04, -1.900e+00, -5.955e+04], dtype=float16)], 1)
(['int8'], [array([[14], [10]], dtype=int8)], 1)
4. array_values - It works in a similar way as the dtype_and_values function, with the only difference being, here an extensive set of parameters and sub-strategies are used to generate array values. For example-:
>>> strategy = helpers.array_values(
dtype="int32",
shape=(3,),
min_value=0,
exclude_min=True,
large_abs_safety_factor=2,
safety_factor_scale="linear")
>>> print_hypothesis_examples(strategy, 2)
array([57384, 25687, 248], dtype=int32)
array([1, 1, 1], dtype=int32)
- array_dtypes - As the name suggests, this will generate arbitrary sequences of valid float data types.
The sequence parameters like min_size, and max_size, are specified at test time based on the function. This is what the function returns -:
# A sequence of floats with arbitrary lengths ranging from [1,5]
>>> print_hypothesis_examples(array_dtypes(helpers.ints(min_value=1, max_value=5)))
['float16', 'float32', 'float16', 'float16', 'float32']
['float64', 'float64', 'float32', 'float32', 'float16']
This function should be used whenever we are testing an ivy function that accepts at least one array as an input.
array_bools - This function generates a sequence of boolean values. For example-:
>>> print_hypothesis_examples(array_bools(na = helpers.ints(min_value=1, max_value=5)))
[False, True, True, False, True]
[False]
This function should be used when a boolean value is to be associated for each value of the other parameter, when generated by a sequence. For example, in test_concat, we are generating a list of inputs of the dimension (2,3), and for each input we have three boolean values associated with it that define additional parameters(container, as_variable, native_array). Meaning if the input is to be treated as a container, at the same time, is it a variable or a native array.
lists - As the name suggests, we use it to generate lists composed of anything, as specified by the user. For example in test_device file, it is used to generate a list of array_shapes, in test_manipulation, it is used to generate a list of common_shapes, and more in test_layers. The function takes in 3 arguments, first is the strategy by which the elements are to be generated, in majority of the cases this is helpers.ints, with range specified, and the other arguments are sequence arguments as specified in array_dtypes. For example -:
>>> print_hypothesis_examples(lists(helpers.ints(min_value=1, max_value=6), min_size = 0,max_size = 5))
[2, 5, 6]
[1]
The generated values are then passed to the array creation functions inside the test function as tuples.
valid_axes - This function generates valid axes for a given array dimension. For example -:
>>> print_hypothesis_examples(valid_axes(helpers.ints(min_value=2, max_value=3), size_bounds = [1,3]))
(-3, 1, -1)
(1, -2)
It should be used in functions which expect axes as a required or an optional argument.
integers - This is similar to the
helpers.intsstrategy, with the only difference being that here the range can either be specified manually, or a shared key can be provided. The way shared keys work has been discussed in the Important Strategies sections above.reshape_shapes - This function returns a valid shape after a reshape operation is applied given as input of any arbitrary shape. For example-:
>>> print_hypothesis_examples(reshape_shapes([3,3]), 3)
(9, 1)
(9,)
(-1,)
It should be used in places where broadcast operations are run, either as a part of a larger computation or in a stand-alone fashion.
subsets - As the function name suggests, it generates subsets of any sequence, and returns that subset as a tuple. For example-:
>>> some_sequence = ['tensorflow', 1, 3.06, 'torch', 'ivy', 0]
>>> print_hypothesis_examples(subsets(some_sequence), 4)
('tensorflow', 'ivy', 0)
('tensorflow', 1, 3.06, 'torch', 'ivy')
('tensorflow', 1, 'torch', 0)
(1, 3.06)
It ensures full coverage of the values that an array can have, given certain parameters like allow_nan, allow_subnormal, allow_inf. Such parameters usually test the function for edge cases. This function should be used in places where the result doesn’t depend on the kind of value an array contains.
get_shape - This is used to generate any arbitrary shape.If allow_none is set to
True, then an implicit st.one_of strategy is used, wherein the function will either generateNoneas shape or it will generate a shape based on the keyword arguments of the function. For example -:
>>> print_hypothesis_examples(
get_shape(
allow_none = True, min_num_dims = 2,
max_num_dims = 7, min_dim_size = 2
), 3
)
(5, 5, 8)
(4, 3, 3, 4, 9, 9, 8)
(9, 9, 3, 5, 6)
get_bounds - It’s often the case that we need to define a lower and an upper limit for generating certain values, like floats, sequences, arrays_values etc. This strategy can be put to use when we want our function to pass on values in any range possible, or we’re unsure about the limits. We can also use the function to generate a list of possible bounds wherein the function fails. For example-:
>>> input_dtype = helpers.get_dtypes("integer").example()
>>> print_hypothesis_examples(get_bounds(input_dtype.example()))
(73, 36418)
(213, 21716926)
Note - Under the hood, array_values strategy is called if the data type is integer, and none_or_list_of_floats is called when the data type is float.
get_probs - This is used to generate a tuple containing two values. The first one being the unnormalized probabilities for all elements in a population, the second one being the population size. For example-:
>>> input_dtype = helpers.get_dtypes("float").example()
>>> print_hypothesis_examples(get_probs(input_dtype.example()))
([[6.103515625e-05, 1.099609375], [1.0, 6.103515625e-05], [1.0, 1.0], [0.5, 6.103515625e-05]], 2)
Such strategies can be used to test statistical and probabilistic functions in Ivy.
get_axis - Similar to the valid_axes strategy, it generates an axis given any arbitrary shape as input. For example-:
>>> print_hypothesis_examples(get_axis(shape = (3,3,2)))
(-1,)
(-2, -1)
num_positional_args - A helper function which generates the number of positional arguments, provided a function name from any ivy submodule. For example -:
>>> print_hypothesis_examples(num_positional_args("matmul"), 3)
2
0
0
This function generates any number of positional arguments within the range [0, number_positional_arguments]. It can be helpful when we are testing a function with a varied number of arguments.
How to write Hypothesis Tests effectively#
It would be helpful to keep in mind the following points while writing test -:
Don’t use
data.drawin the function body.Don’t use any unreproducible data generation (i.e. np.random_uniform) in the function body.
Don’t skip anything or use return statement in the function body.
The function should only call helpers.test_function, and then possibly perform a custom value test if
test_values=Falsein the arguments.We should add as many possibilities as we can while generating data, covering all the function arguments.
If you find yourself using repeating some logic which is specific to a particular submodule, then create a private helper function and add this to the submodule.
If the logic is general enough, this can instead be added to the
helpers, enabling it to be used for tests in other submodules
Testing Partial Mixed Functions#
As explained in the Function Types section, partial mixed functions are a special type of mixed functions that either utilize the compositional implementation
or the primary implementation depending on some conditions on the input. Therefore, the data-types supported by partial mixed functions depend on which implementation will
be used for the given input. For example, when function_supported_dtypes is called with respect to ivy.linear with torch backend, the following output is returned:
{'compositional': ('float32', 'int8', 'uint8', 'float64', 'int16', 'int32', 'int64'), 'primary': ('bool', 'float32', 'int8', 'uint8', 'float64', 'int64', 'int16', 'int32')}
As can be seen from the above output that the data-types supported will depend on the implementation used for the given input. It’s because of this reason that we need a slightly
different pipeline for testing partial mixed functions. Basically, while writing the strategies for the tests of these functions, we need to first determine which implementation
will be used and then based on that generate the data to test the function. Here’s an example from the test of ivy.linear function:
def x_and_linear(draw):
mixed_fn_compos = draw(st.booleans())
is_torch_backend = ivy.current_backend_str() == "torch"
dtype = draw(
helpers.get_dtypes("numeric", full=False, mixed_fn_compos=mixed_fn_compos)
)
in_features = draw(
helpers.ints(min_value=1, max_value=2, mixed_fn_compos=mixed_fn_compos)
)
out_features = draw(
helpers.ints(min_value=1, max_value=2, mixed_fn_compos=mixed_fn_compos)
)
x_shape = (
1,
1,
in_features,
)
weight_shape = (1,) + (out_features,) + (in_features,)
# if backend is torch and we're testing the primary implementation
# weight.ndim should be equal to 2
if is_torch_backend and not mixed_fn_compos:
weight_shape = (out_features,) + (in_features,)
bias_shape = (
1,
out_features,
)
x = draw(
helpers.array_values(dtype=dtype[0], shape=x_shape, min_value=0, max_value=10)
)
weight = draw(
helpers.array_values(
dtype=dtype[0], shape=weight_shape, min_value=0, max_value=10
)
)
bias = draw(
helpers.array_values(
dtype=dtype[0], shape=bias_shape, min_value=0, max_value=10
)
)
return dtype, x, weight, bias
As can be seen from the above code, a boolean parameter mixed_fn_compos is generated first to determine whether to generate test data for
the compositional implementation or the primary one. When it is equal to True, the relevant data for the compositional implementation should
be generated and when False, data corresponding to the primary implementation should be generated. Another boolean, is_torch_backend
is to be used to determine if the current backend is torch. Then these booleans are used together in this if condition:
if is_torch_backend and not mixed_fn_compos and weight_shape is updated to be 2 dimensional because the torch backend implementation
only supports 2 dimensional weights. Notice that the parameter mixed_fn_compos is also be passed to helpers.get_dtypes and
helpers.ints functions so that the dtypes corresponding to the implementation to be tested are returned. In general, helpers.get_dtypes,
helpers.ints, helpers.floats, and helpers.numbers all have the mixed_fn_compos argument which must be supplied for the correct
dtypes to be returned. In case the backend has a partial mixed implementation, the dtypes corresponding to either the compositional or the primary
implementation are returned, depending on the value of the parameter, and otherwise the parameter is ignored. Rest of the testing pipeline is the
same is as other functions.
Bonus: Hypothesis’ Extended Features#
Hypothesis performs Automated Test-Case Reduction. That is, the given decorator strives to report the simplest set of input values that produce a given error. For the code block below-:
@given(
data = st.data(),
input_dtype = st.sampled_from(ivy_np.valid_float_dtypes),
as_variable=st.booleans()
)
def test_demo(
data,
input_dtype,
as_variable,
):
shape = data.draw(get_shape(min_num_dims=1))
#failing assertions
assert as_variable == False
assert shape == 0
test_demo()
Hypothesis reports the following -:
Falsifying example: failing_test(
data=data(...), input_dtype='float16', as_variable=True,
)
Draw 1: (1,)
Traceback (most recent call last):
File "<file_name>.py" line "123", in test_demo
assert as_variable == False
AssertionError
Falsifying example: failing_test(
data=data(...), input_dtype='float16', as_variable=False,
)
Draw 1: (1,)
assert shape == 0
AssertionError
As can be seen from the output above, the given decorator will report the simplest set of input values that produce a given error. This is done through the process of Shrinking.
Each of the Hypothesis’ strategies has it’s own prescribed shrinking behavior. For integers, it will identify the integer closest to 0 that produces the error at hand. Checkout the documentation for more information on shrinking behaviors of other strategies.
Hypothesis doesn’t search for falsifying examples from scratch every time the test is run.
Instead, it saves a database of these examples associated with each of the project’s test functions.
In the case of Ivy, the .hypothesis cache folder is generated if one doesn’t exist, otherwise the existing one is added to it.
We just preserve this folder on the CI, so that each commit uses the same folder, and so it is ignored by git, thereby never forming part of the commit.
–hypothesis-show-statistics
This feature helps in debugging the tests, with methods like note(), custom event()s where addition to the summary, and a variety of performance details are supported. Let’s look at the function test_gelu -:
run pytest —hypothesis-show-statistics <test_file>.py
This test runs for every backend, and the output is shown below-:
Jax

Numpy
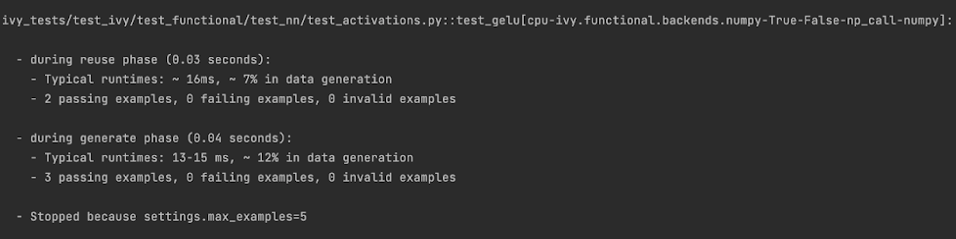
Tensorflow
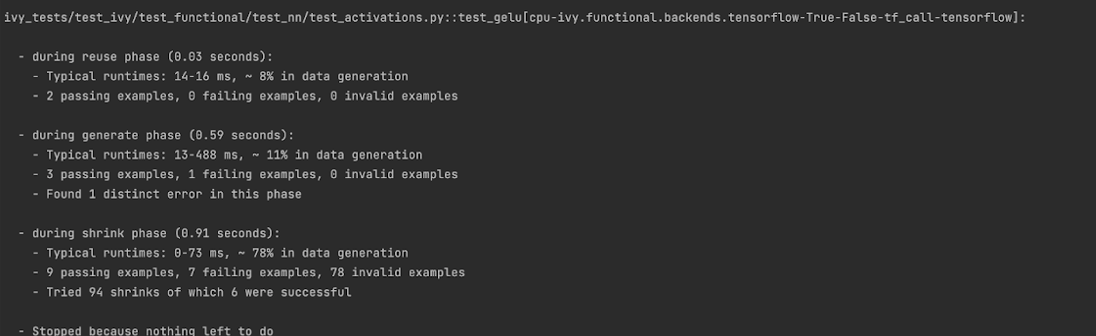
Torch
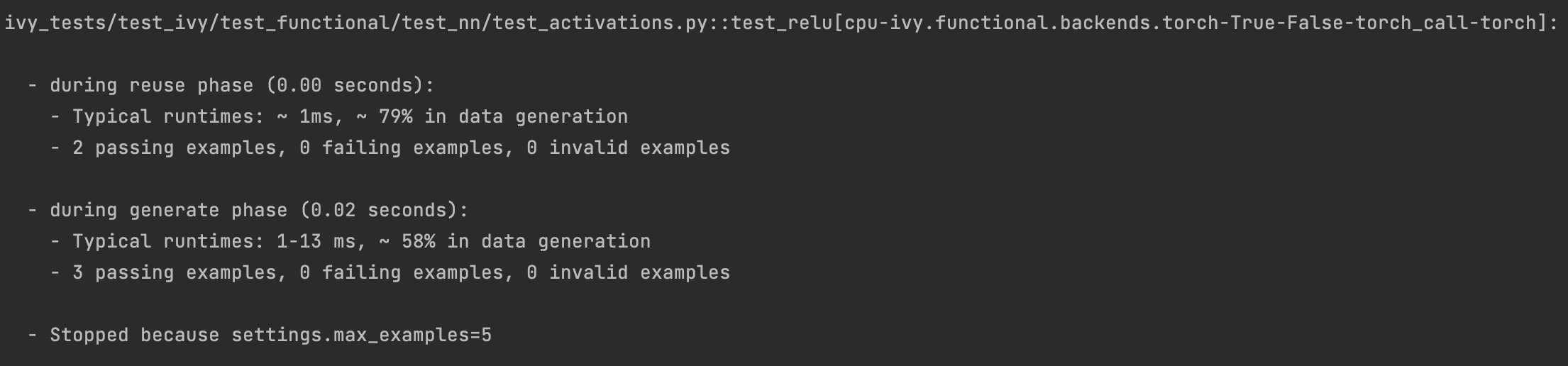
It can be seen that the function doesn’t fail for Jax, Numpy, and Torch, which is clearly not the case with Tensorflow, wherein 7 examples failed the test. One important thing to note is the number of values for which Shrinking (discussed in brief above) happened. Statistics for both generate phase, and shrink phase if the test fails are printed in the output. If the tests are re-run, reuse phase statistics are printed as well where notable examples from previous runs are displayed.
Another argument which can be specified for a more detailed output is hypothesis-verbosity = verbose. Let’s look at the newer output, for the same example -:
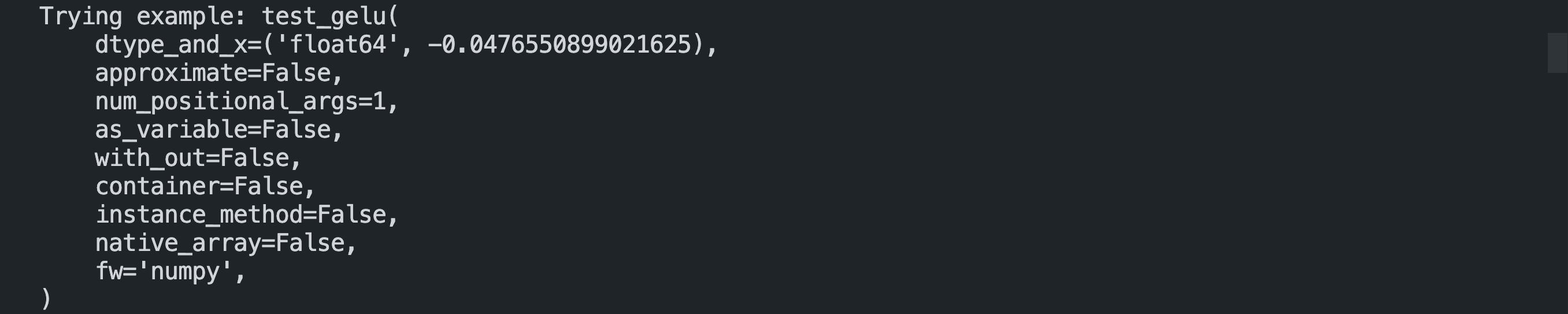
Like the output above, Hypothesis will print all the examples for which the test failed, when verbosity is set.
Some performance related settings which might be helpful to know are-:
max_examples - The number of valid examples Hypothesis will run. It usually defaults to 100. Turning it up or down will have an impact on the speed as well as the rigorousness of the tests.
deadline - If an input takes longer than expected, it should be treated as an error. It is useful to detect weird performance issues.
Self-Consistent and Explicit Testing#
The Hypothesis data generation strategies ensure that we test for arbitrary variations in the function inputs, but this makes it difficult to manually verify ground truth results for each input variation.
Therefore, we instead opt to test for self-consistency against the same Ivy function with a NumPy backend.
This is handled by test_array_function(), which is a helper function most unit tests defer to.
This function is explained in more detail in the following sub-section.
For primary functions, this approach works well. Each backend implementation generally wraps an existing backend function, and under the hood these implementations vary substantially. This approach then generally suffices to correctly catch bugs for most primary functions.
However, for compositional and mixed functions, then it’s more likely that a bug could be missed. With such functions, it’s possible that the bug exists in the shared compositional implementation, and then the bug would be systematic across all backends, including the ground truth NumPy which the value tests for all backends compare against.
Therefore, for all mixed and compositional functions, the test should also be appended with known inputs and known ground truth outputs, to safeguard against this inability for test_array_function() to catch systematic errors.
These should be added using pytest.mark.parametrize.
However, we should still also include test_array_function() in the test, so that we can still test for arbitrary variations in the input arguments.
test_array_function#
The helper test_array_function tests that the function:
can handle the
outargument correctlycan be called as an instance method of the ivy.Array class
can accept ivy.Container instances in place of any arguments for nestable functions, applying the function to the leaves of the container, and returning the resultant container
can be called as an instance method on the ivy.Container
is self-consistent with the function return values when using a NumPy backend
array in the name test_array_function() simply refers to the fact that the function in question consumes arrays in the arguments.
So when should test_array_function() be used?
The rule is simple, if the test should not pass any arrays in the input, then we should not use the helper test_array_function().
For example, ivy.num_gpus() does not receive any arrays in the input, and so we should not make use of test_array_function() in the test implementation.
Running Ivy Tests#
The CI Pipeline runs the entire collection of Ivy Tests for the module that is being updated on every push to the repo.
You will need to make sure the Ivy Test is passing for each Ivy function you introduce/modify. If a test fails on the CI, you can see details about the failure under Details -> Run Ivy <module> Tests as shown in `CI Pipeline`_.
You can also run the tests locally before making a PR. The instructions differ according to the IDE you are using. For PyCharm and Visual Studio Code you can refer to the Setting Up Testing in PyCharm section and Setting up for Free section respectively.
Re-Running Failed Ivy Tests#
When a Hypothesis test fails, the falsifying example is printed on the console by Hypothesis.
For example, in the test_result_type Test, we find the following output on running the test:
Falsifying example: test_result_type(
dtype_and_x=(['bfloat16', 'int16'], [-0.9090909090909091, -1]),
as_variable=False,
num_positional_args=2,
native_array=False,
container=False,
instance_method=False,
fw='torch',
)
It is always efficient to fix this particular example first, before running any other examples.
In order to achieve this functionality, we can use the @example Hypothesis decorator.
The @example decorator ensures that a specific example is always tested, on running a particular test.
The decorator requires the test arguments as parameters.
For the test_result_type Test, we can add the decorator as follows:
@example(
dtype_and_x=(['bfloat16', 'int16'], [-0.9090909090909091, -1]),
as_variable=False,
num_positional_args=2,
native_array=False,
container=False,
instance_method=False,
fw='torch',
)
This ensures that the given example is always tested while running the test, allowing one to debug the failure efficiently.
Round Up
This should have hopefully given you a good feel for how the tests are implemented in Ivy.
If you have any questions, please feel free to reach out on discord in the ivy tests thread!